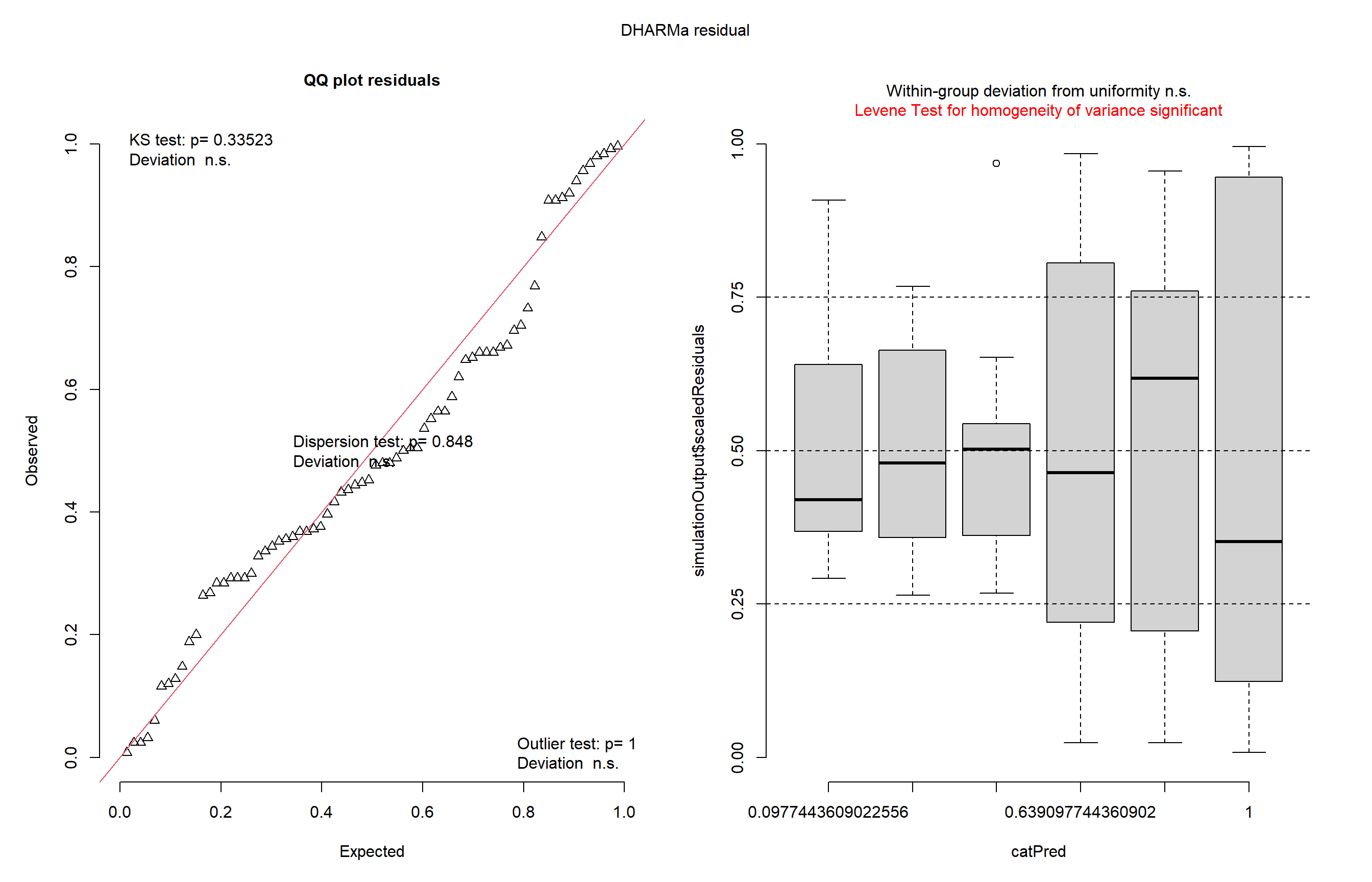
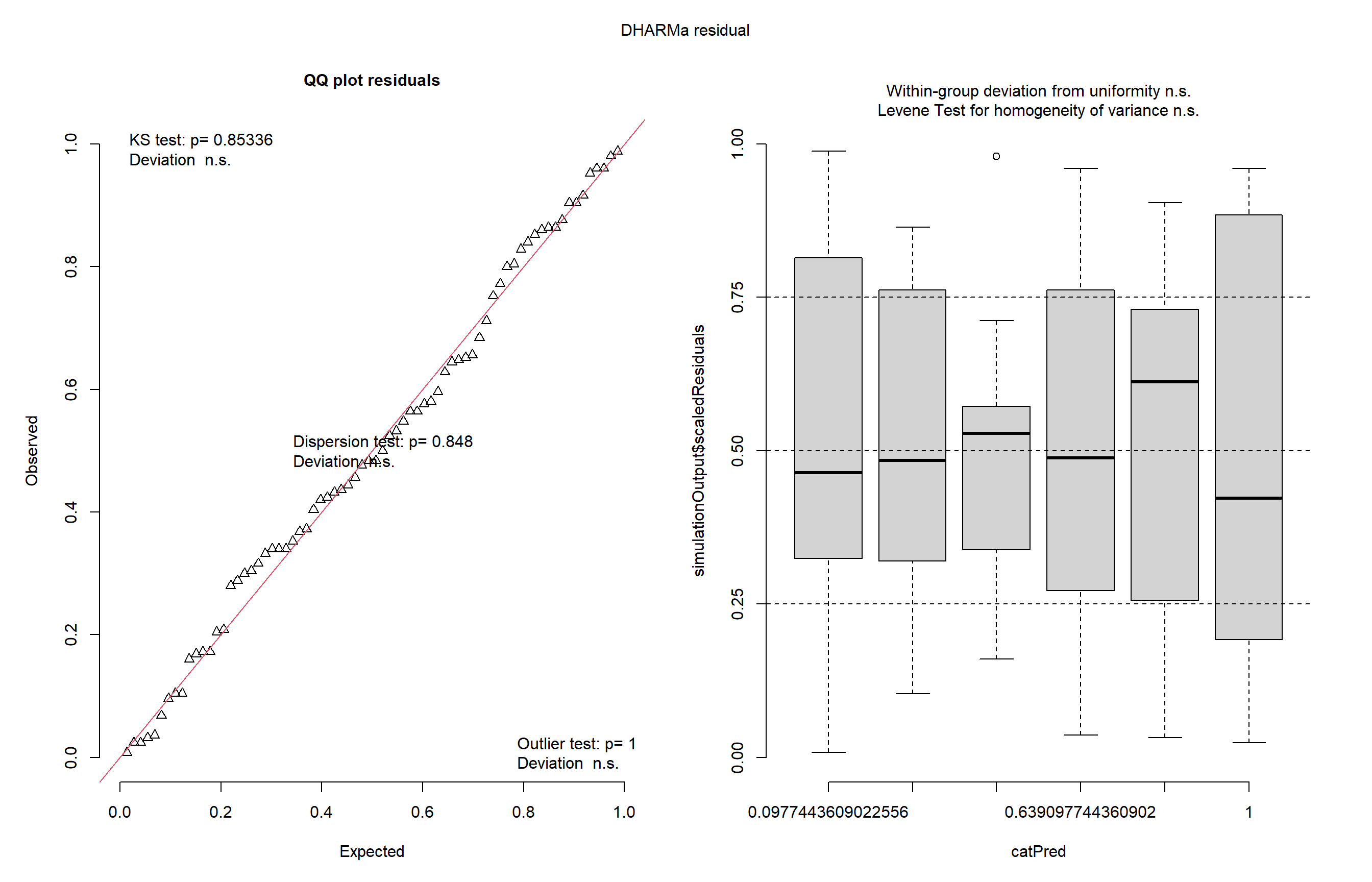
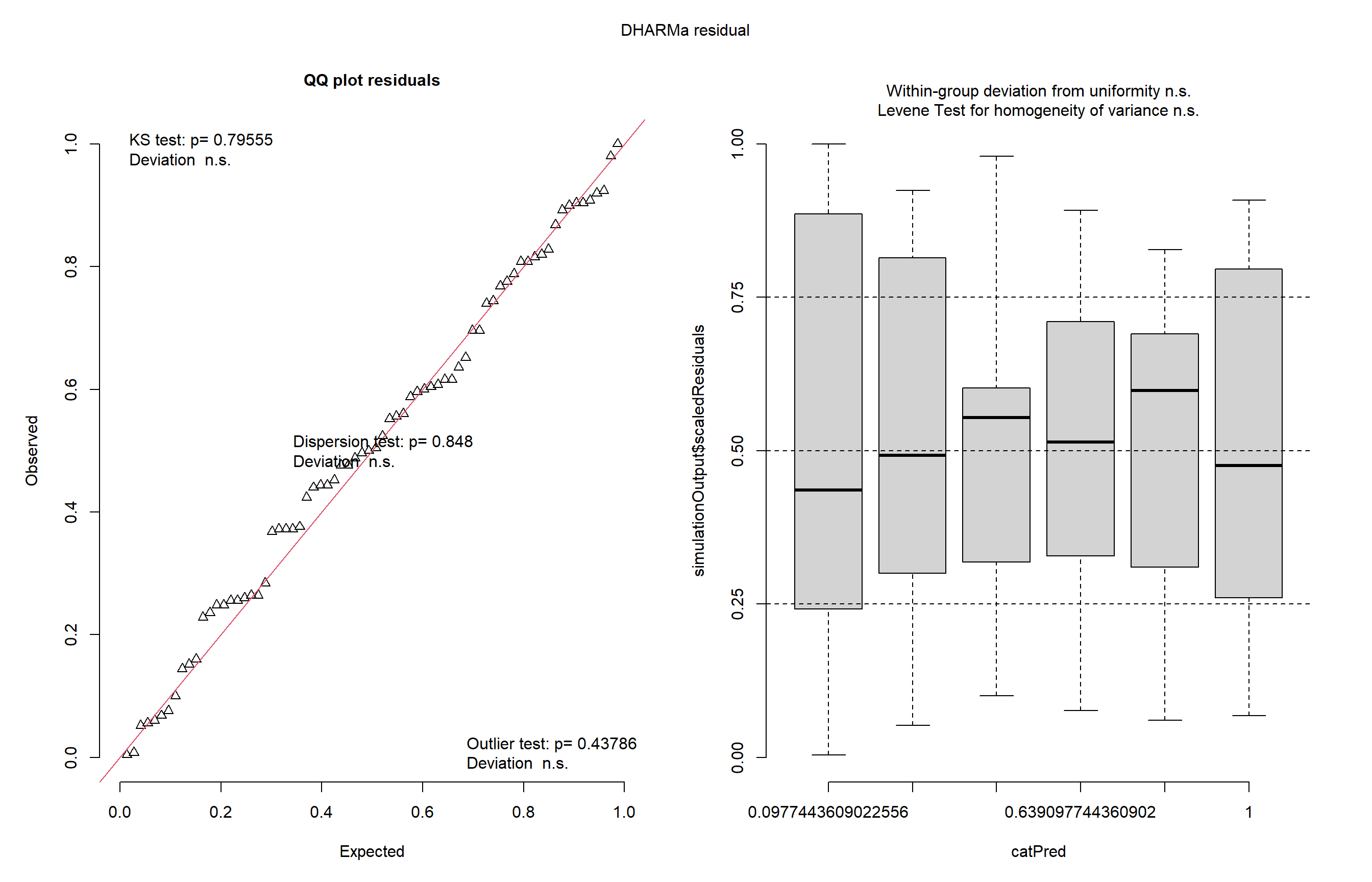
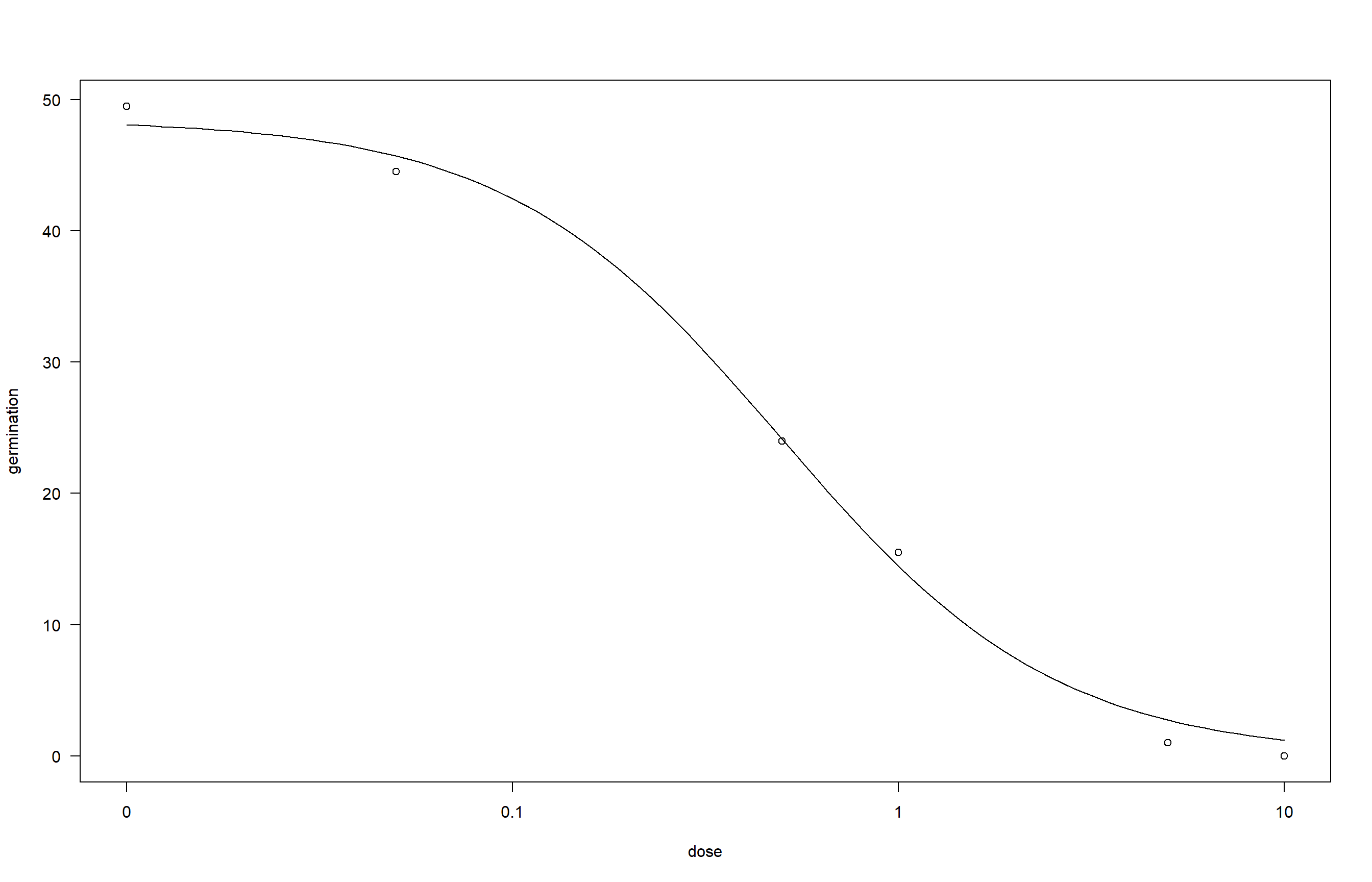library(MASS)insects <- InsectSpraysm1 <-lm(count ~ spray, data = insects)library(DHARMa)plot(simulateResiduals(m1))
#não atendeu ao pressuposto de homogeneidade então fizemos transformação dos dados primeiro por raiz quadrada. m1 <-lm(sqrt(count) ~ spray, data = insects)m1
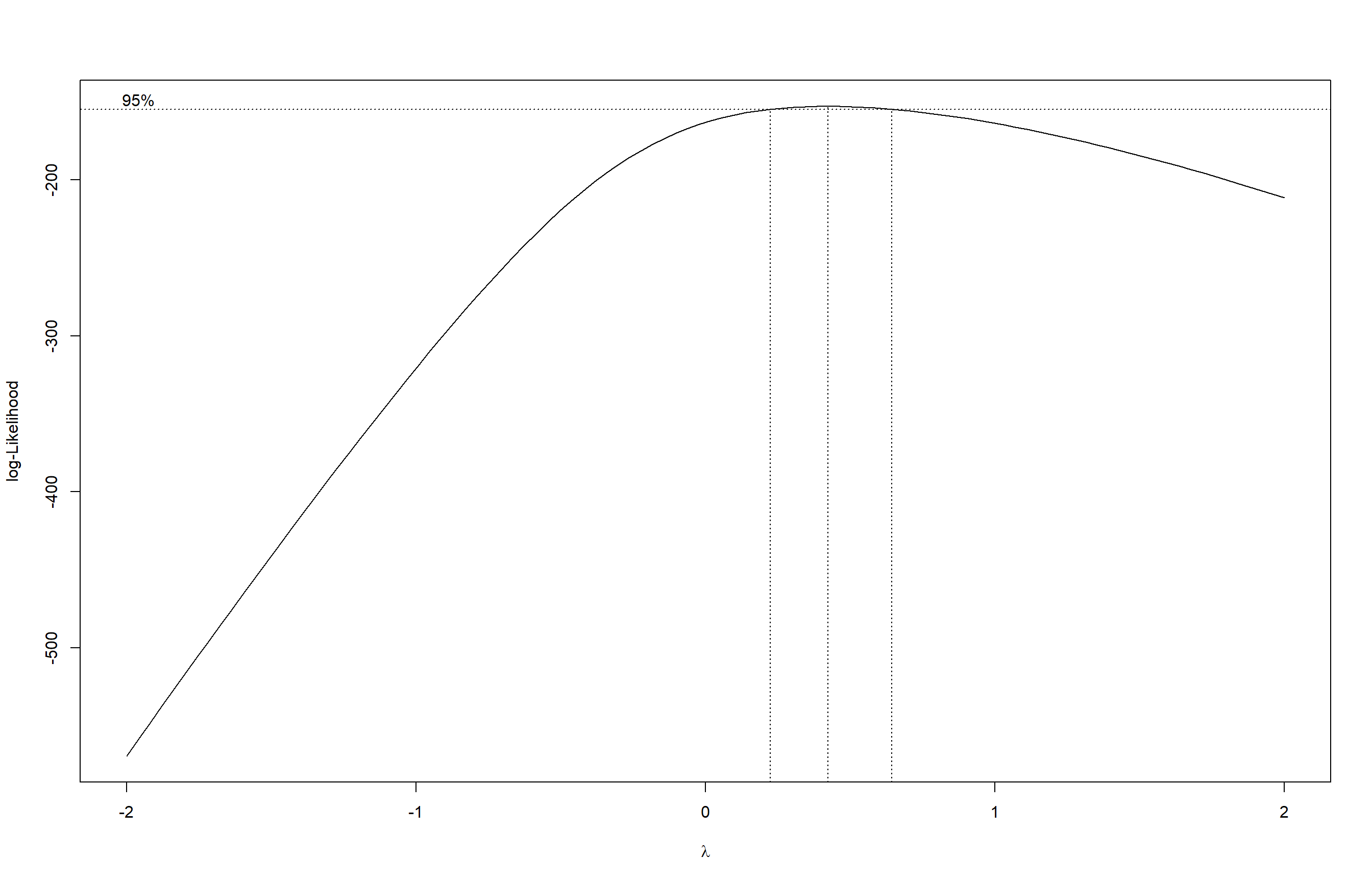
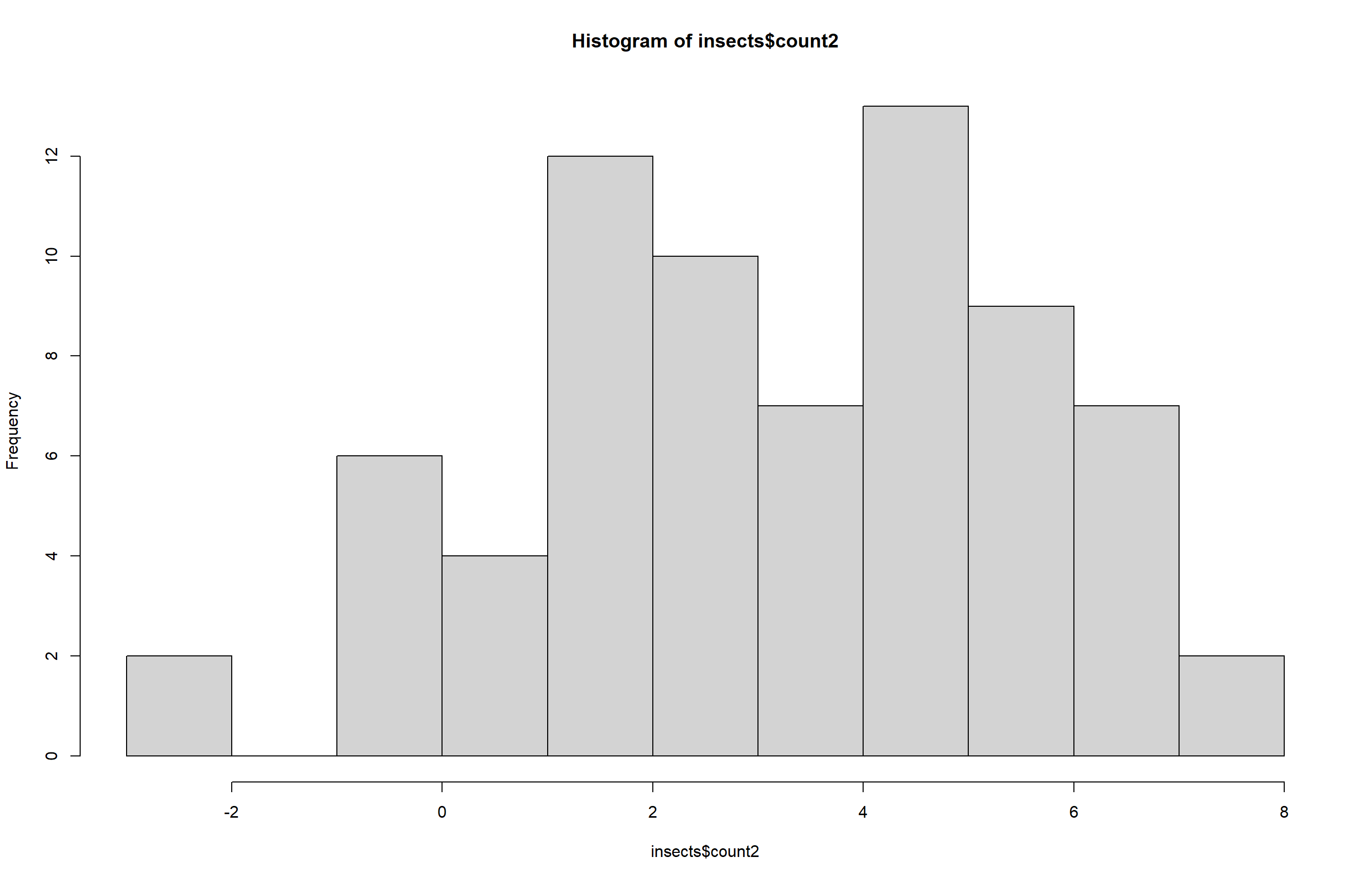
Aqui carregamos o conjunto de dados InsectSprays e ajustamos um modelo linear para verificar o efeito do tipo de inseticida sobre a contagem de insetos mortos. Em seguida, utilizamos o pacote DHARMa para avaliar os resíduos do modelo e verificamos possíveis desvios da normalidade. Depois aplicamos a transformação de Box-Cox, para melhorar a adequação do modelo e identificando o melhor valor de lambda. Também testamos a transformação por raiz quadrada para comparação.
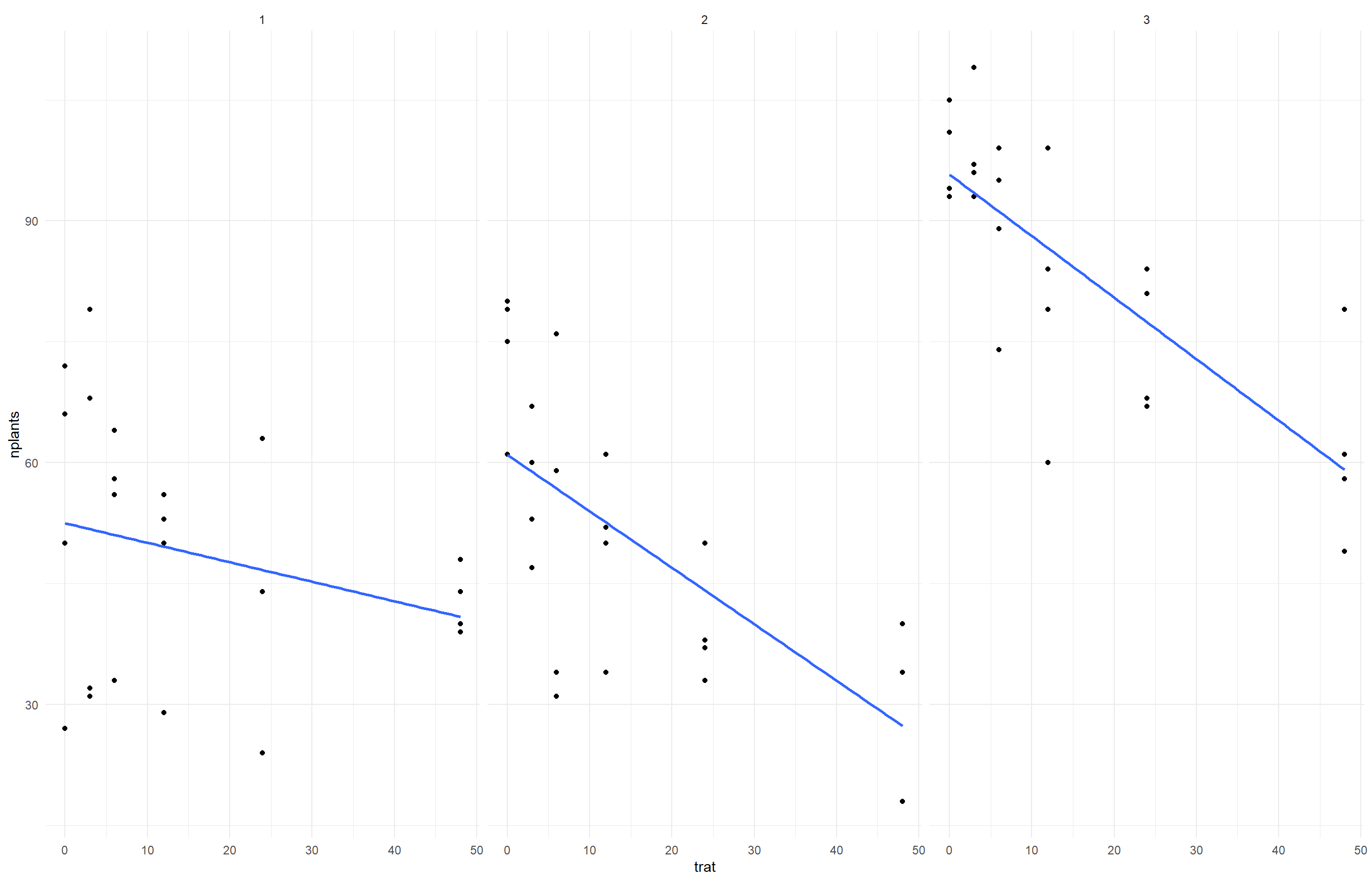
Aqui importamos e fizemos a visualização dos dados relacionados à emergência de plantas em função da porcentagem de inóculo nas sementes. utilizamos o ggplot2 para criar gráficos de dispersão entre o tratamento (trat) e o número de plantas emergidas (nplants), separando os gráficos por experimento (exp). Também adicionamos uma linha de tendência linear para facilitar a visualização do comportamento dos dados em cada experimento.
Call:
lm(formula = nplants ~ trat, data = exp3)
Residuals:
Min 1Q Median 3Q Max
-26.5887 -3.9597 0.7177 5.5806 19.8952
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 95.7500 2.9529 32.425 < 2e-16 ***
trat -0.7634 0.1306 -5.847 6.97e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 10.53 on 22 degrees of freedom
Multiple R-squared: 0.6085, Adjusted R-squared: 0.5907
F-statistic: 34.19 on 1 and 22 DF, p-value: 6.968e-06
Aqui realizamos análises para cada um dos experimentos da planilha importada anteriormente. Filtramos os dados por experimento e ajustamos modelos lineares para avaliar a relação entre o percentual de inóculo (trat) e o número de plantas emergidas (nplants). Para cada experimento, usamos a função lm() e analisamos os resultados por meio do summary(), permitindo identificar a significância e o efeito do tratamento em cada caso específico.
library(lme4)m_misto <-lmer(nplants ~ trat + (1| exp/bloco), data = estande)summary(m_misto)
Linear mixed model fit by REML ['lmerMod']
Formula: nplants ~ trat + (1 | exp/bloco)
Data: estande
REML criterion at convergence: 575.8
Scaled residuals:
Min 1Q Median 3Q Max
-2.21697 -0.63351 0.04292 0.67094 1.92907
Random effects:
Groups Name Variance Std.Dev.
bloco:exp (Intercept) 54.76 7.40
exp (Intercept) 377.43 19.43
Residual 134.99 11.62
Number of obs: 72, groups: bloco:exp, 12; exp, 3
Fixed effects:
Estimate Std. Error t value
(Intercept) 69.74524 11.57191 6.027
trat -0.56869 0.08314 -6.840
Correlation of Fixed Effects:
(Intr)
trat -0.111
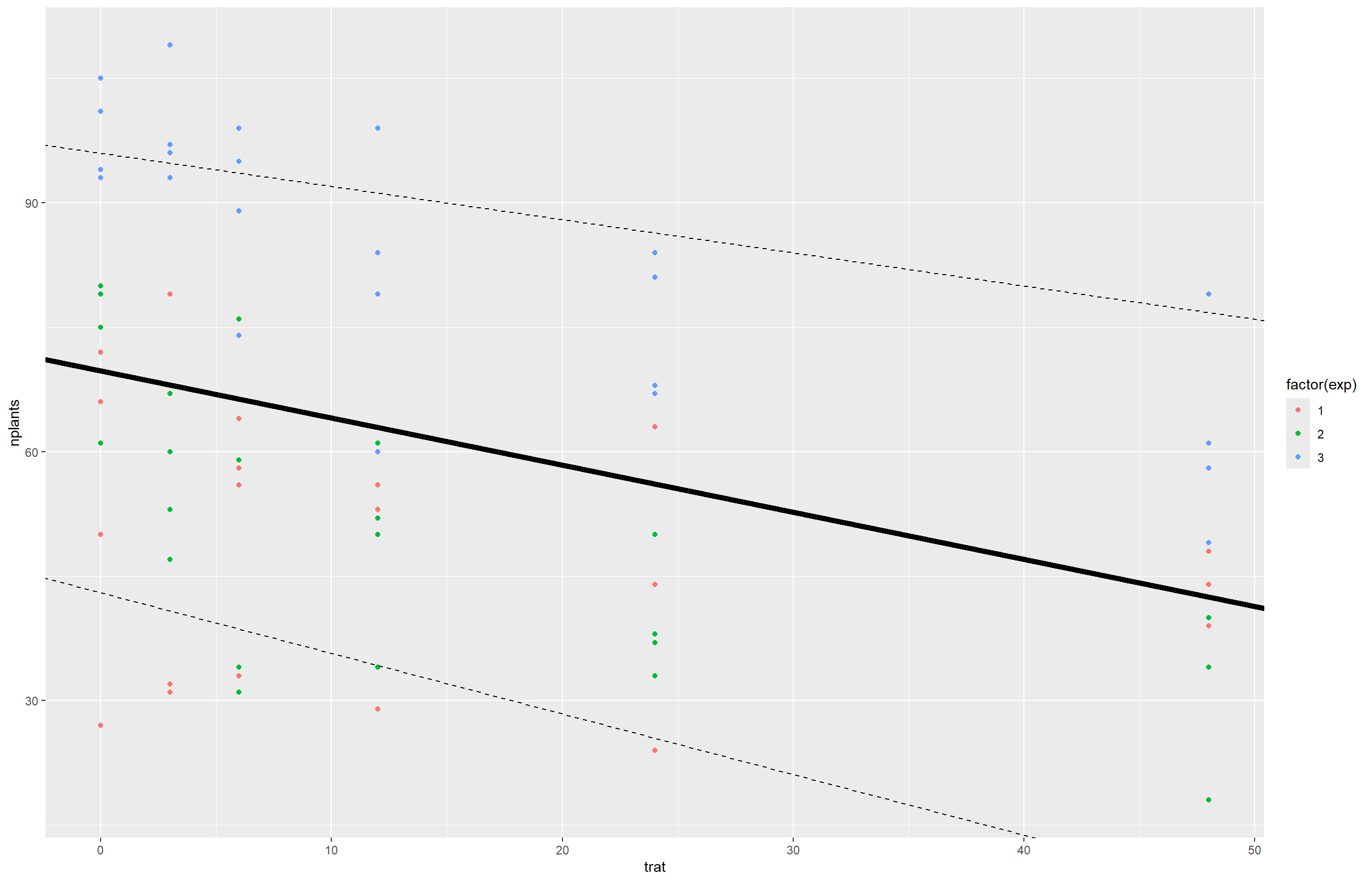
Aqui realizamos uma análise com modelo misto para considerar variações entre experimentos e blocos. Fizemos isso ajustando um modelo misto linear com o pacote lme4, considerando o efeito fixo do tratamento (trat) e os efeitos aleatórios dos blocos dentro dos experimentos ((1 | exp/bloco)). Avaliamos o modelo com summary(), obtivemos os intervalos de confiança dos parâmetros com confint() e testamos a significância dos efeitos com a função Anova() do pacote car. Por fim, criamos um gráfico com os pontos dos dados coloridos por experimento e adicionamos retas com diferentes interceptos e inclinações para representar tendências gerais e específicas, comparando possíveis ajustes.
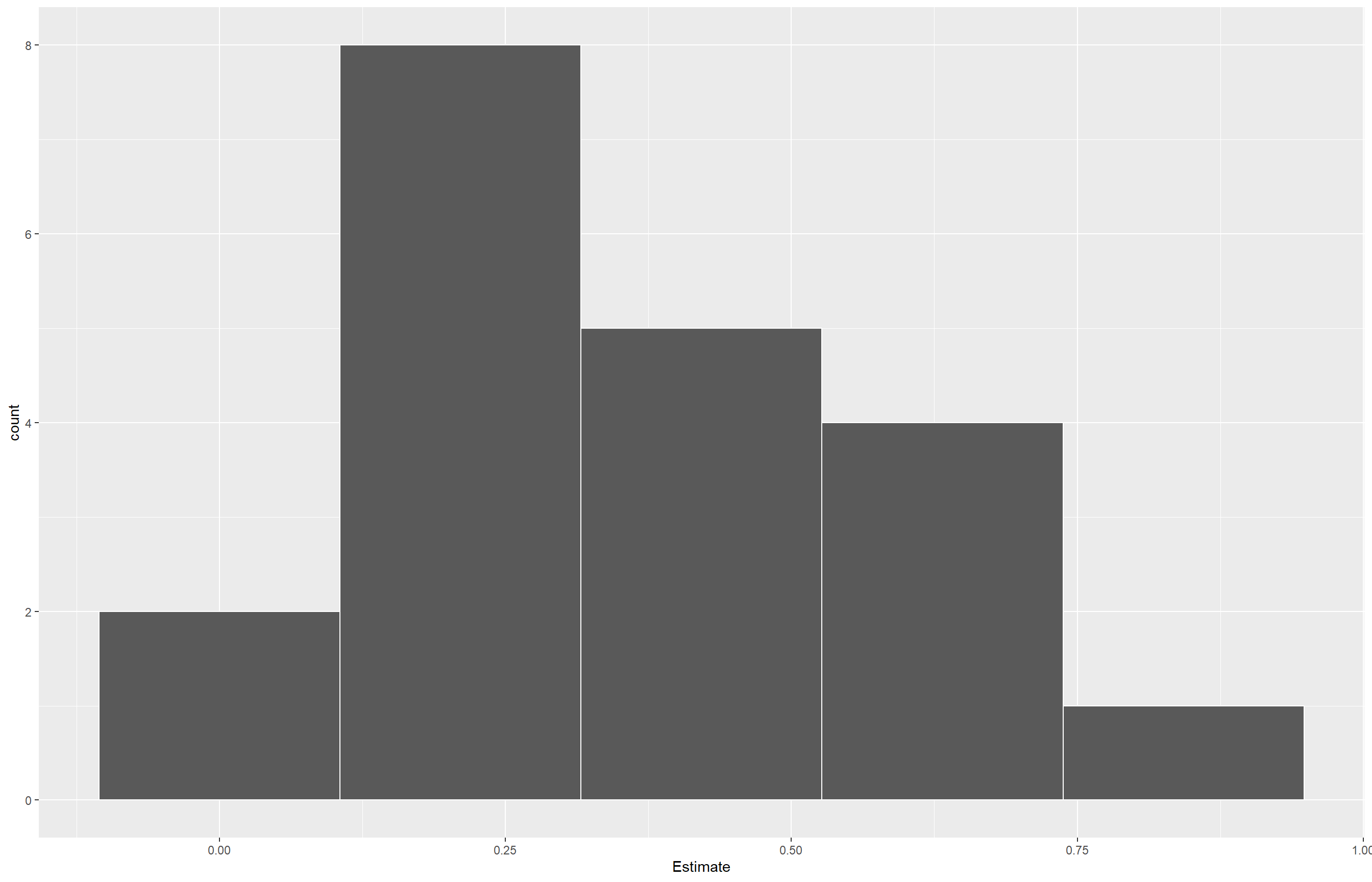
df_ec50 |>ggplot(aes(x = Estimate)) +geom_histogram(bins =5, color ="white")
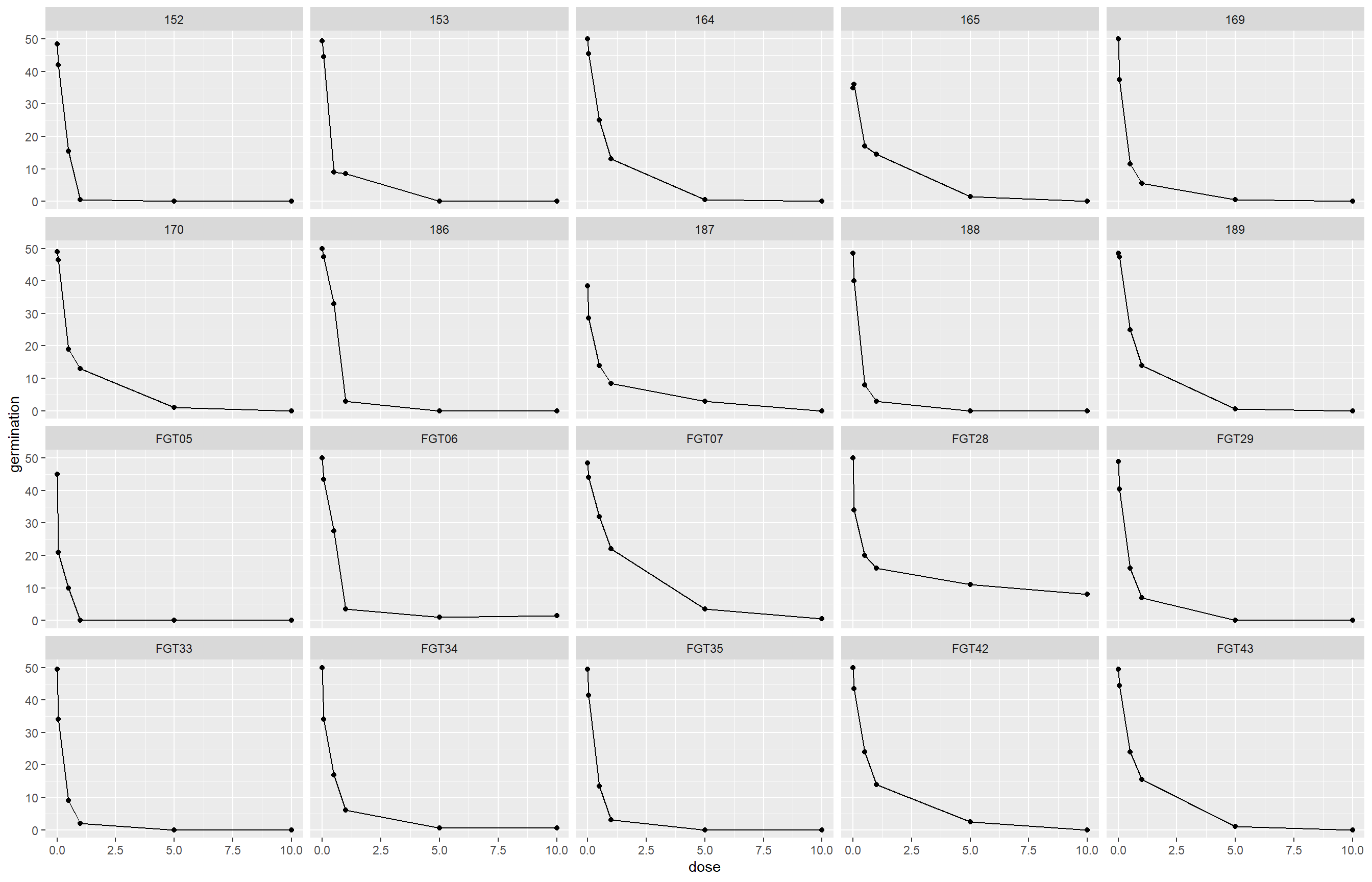
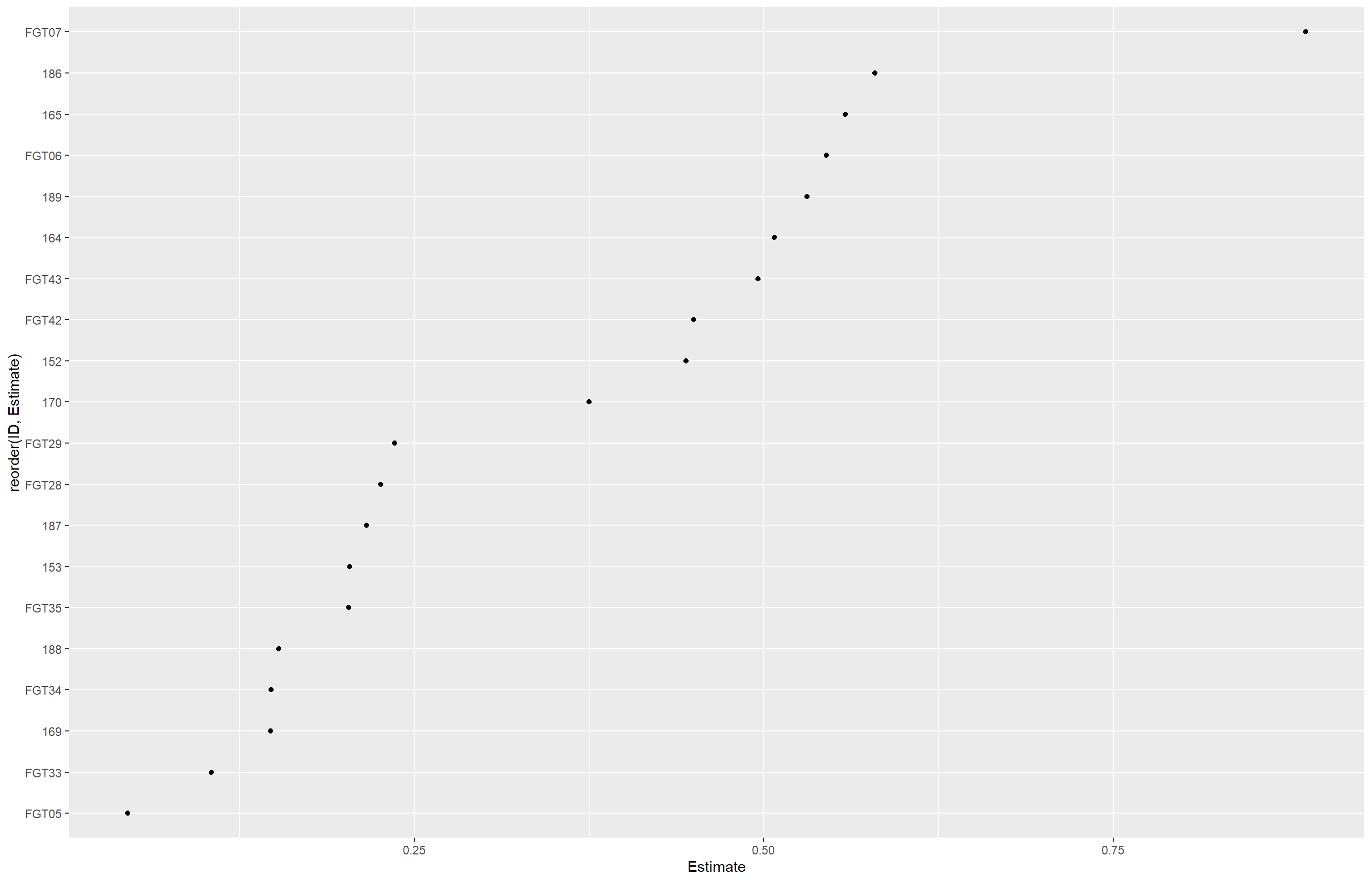
Aqui importamos os dados de germinação de esporos de diferentes isolados sob diferentes doses de tratamento, depois calculamos a média de germinação por isolado e dose e visualizamos os resultados com gráficos de dispersão e linhas. Selecionamos o isolado FGT43 e ajustamos um modelo não linear com o pacote drc, estimando a EC50 e visualizando o ajuste. Em seguida, utilizamos o pacote ec50estimator para estimar a EC50 de todos os isolados ao mesmo tempo, por estado. Por fim, apresentamos os resultados em gráfico de pontos ordenados e histograma das EC50s para avaliar a variabilidade entre os isolados.